Table of contents
- What “scalability” actually means for a non-technical founder
- The moment your app breaks: what happens under the hood
- How BaaS platforms handle the traffic spike for you
- The three layers of scale: users, data, and geography
- Planning for growth before it hits: a founder’s checklist
- When to upgrade, optimize, or rethink your backend plan
Most founders think about scalability the same way they think about retirement savings — something genuinely important that becomes urgent later, once the more immediate problems are solved. Launch first, get users, find product-market fit, then worry about whether the infrastructure can handle success. It is a reasonable instinct, and for the first few months it is usually correct.
The problem is that the moment scalability stops being theoretical arrives without warning and with terrible timing. It tends to happen during a launch, a press mention, a viral social post, or a well-timed product hunt campaign — exactly the moments when your app needs to perform at its best in front of the largest audience it has ever had. The founders who navigate those moments smoothly are not the ones who got lucky with robust infrastructure. They are the ones who understood what scalability actually requires before they needed it.
This article is not about turning you into a backend engineer. It is about giving you the mental models and decision-making frameworks to think clearly about your app’s ability to grow — so that when success arrives faster than expected, you are ready for it rather than scrambling to catch up.
What “scalability” actually means for a non-technical founder
The word scalability gets used in technical conversations with a specificity it rarely receives in business ones. Developers talk about horizontal scaling, vertical scaling, load balancing, and distributed systems. Founders hear a general concept that means something like “the app can handle more users.” Both definitions are correct, but only one of them is useful for making business decisions.
For a non-technical founder, scalability is best understood as the relationship between growth and performance. A scalable app is one where adding more users does not proportionally degrade the experience for existing ones. An app that loads in 800 milliseconds for your first hundred users and still loads in 800 milliseconds for your first ten thousand users is scalable in the ways that matter to your business. An app that loads in 800 milliseconds at a hundred users and takes four seconds at ten thousand has a scalability problem, regardless of how the underlying architecture is described.
The practical implication of this definition is that scalability is not a binary property your app either has or lacks. It is a spectrum, and where your app sits on that spectrum at any given time depends on the relationship between your current infrastructure capacity and your current usage demands. A small app on a modest backend plan can be perfectly scalable for its current stage. The same app on the same plan six months later, with ten times the users, may have crossed into territory where the infrastructure is limiting the experience.
Understanding scalability as a relationship rather than a fixed characteristic changes how you think about infrastructure decisions. The question is not “is my app scalable?” in the abstract. It is “is my current infrastructure matched to my current and near-future usage?” That is a question with a concrete, answerable shape, and it is one you can evaluate without a computer science background.
The restaurant that only has five tables
A useful analogy for non-technical founders is a restaurant that opens with five tables. At launch, five tables is exactly right. The kitchen can handle the orders, the staff can manage the service, and every customer gets a good experience. The restaurant is perfectly scalable for its current demand.
Now imagine that a food blogger posts a glowing review and suddenly fifty people show up on a Saturday night expecting a table. The five-table restaurant is no longer matched to its demand. The kitchen is overwhelmed, service slows down, customers wait too long, and some of them leave before being seated. The food has not gotten worse. The staff have not gotten less competent. The infrastructure simply was not built for that volume.
Your app’s backend is the restaurant. Your users are the customers. Scalability planning is the process of deciding, in advance, how many tables you actually need — and having a clear plan for adding more before the Saturday night rush arrives.
Why scalability is a business problem, not just a technical one
The consequences of a scalability failure are not confined to your engineering team. They land directly on your business metrics. A slow or unavailable app during a high-traffic moment means potential users who bounce before they experience your product. It means existing users who encounter degraded performance at the moment they are most likely to recommend it to others. It means support ticket volume that spikes precisely when your team is least equipped to handle it.
The business cost of a scalability incident is rarely captured in a single clean number, but its components are real and measurable. Conversion rates drop when load times increase. Churn accelerates when reliability becomes unpredictable. Word-of-mouth inverts from positive to negative when the experience that prompted someone to share the product is a frustrating one. Scalability is a retention and acquisition problem wearing a technical costume.
The moment your app breaks: what happens under the hood
Most founders experience their first scalability incident the same way. The app has been running smoothly for weeks. Then, in the space of a few minutes, everything changes. Pages stop loading. Users report errors. The support inbox fills up. And somewhere in the middle of trying to understand what is happening, the realization arrives: the infrastructure cannot keep up with what is being asked of it.
Understanding what actually happens during that moment — in plain language, without the technical jargon — is one of the most useful things a non-technical founder can internalize. Not because it will turn you into someone who can fix the problem yourself, but because it will help you recognize the warning signs earlier, communicate more clearly with your team, and make better decisions about prevention.
The chain of events behind every user request
Every time a user does something in your app — opens a page, submits a form, searches for a record, clicks a button — a chain of events is set in motion behind the scenes. The user’s device sends a request to your server. The server receives that request, figures out what is being asked, queries your database for the relevant data, assembles the response, and sends it back. The whole chain, in a healthy app on adequate infrastructure, takes a fraction of a second.
Now consider what happens when a thousand users are doing this simultaneously, on infrastructure provisioned for a hundred. Every link in that chain is being asked to handle ten times its intended load. The server is processing ten times the requests it was designed for. The database is handling ten times the concurrent queries. The network connections between them are saturated. Each individual request, rather than completing in 400 milliseconds, starts taking two seconds, then five, then timing out entirely.
This is not a code failure. Nothing in the application logic has changed. The requests are being handled the same way they always were. The difference is volume, and the infrastructure does not have the capacity to absorb it. Think of it like a single-lane road that works perfectly for everyday traffic but gridlocks the moment an event ends and thousands of cars try to use it simultaneously. The road is not broken. It is simply undersized for the demand being placed on it.
The three bottlenecks that break first
When an app struggles under load, the failure almost never happens everywhere at once. It concentrates at specific bottlenecks — the points in the chain where capacity is most constrained relative to demand.
The first and most common bottleneck is the database. Databases are designed to handle concurrent queries, but every plan has a limit on how many simultaneous connections it can maintain. When that limit is hit, new queries queue up and wait. Each waiting query means a waiting user. As the queue grows, response times climb, users retry their requests, which adds more queries to the queue, which makes the problem worse. This self-reinforcing cycle is one of the reasons database-driven slowdowns escalate quickly once they start.
The second common bottleneck is server compute — the processing power available to handle incoming requests. Every request your server receives requires some amount of computation: parsing the request, executing logic, formatting the response. When compute capacity is saturated, new requests wait in a queue just as they do at the database level. The user experience is identical — slow responses, timeouts, errors — but the source is different, which is why identifying the specific bottleneck matters for choosing the right fix.
The third bottleneck is memory, the working space your server uses to hold data it is actively processing. An application under load needs to hold more information in memory simultaneously than one handling light traffic. When available memory runs out, the server starts using slower disk storage as an overflow, which dramatically degrades performance, or starts dropping requests entirely to protect itself from crashing.
What “crashing” actually means
When founders talk about an app “going down,” they usually mean one of two things. Either the service is completely unavailable — every request fails, the app returns an error page or no response at all — or the service is so severely degraded that it is functionally unavailable for most users even though it is technically still running.
A complete outage typically happens when a server runs out of memory or encounters an unhandled error at high load and restarts itself. During the restart, which might take thirty seconds or several minutes depending on the platform, no requests are processed. For a SaaS product, thirty seconds of complete downtime during a high-traffic moment can mean hundreds of failed sessions and a meaningful number of users who close the tab and do not return.
Severe degradation is in some ways worse than a clean outage because it is harder to diagnose and harder for users to understand. An app that is completely down produces a clear error. An app that takes forty-five seconds to load a page, intermittently times out, and occasionally works normally produces confusion. Users do not know whether to wait, retry, or give up. The ambiguity itself is damaging to trust in a way that a clean, acknowledged outage sometimes is not.
The difference between a spike and sustained growth
It is worth distinguishing between two types of scalability challenges because they require different responses. A traffic spike is a sudden, concentrated surge in usage — the product hunt launch, the press mention, the viral tweet — that pushes your infrastructure beyond its limits for a short period and then subsides. Sustained growth is a gradual, compounding increase in your baseline user activity that eventually outpaces your infrastructure’s capacity over weeks or months.
Spikes are dramatic and visible. They produce sudden incidents that are easy to identify as infrastructure problems. The more insidious challenge is sustained growth, which produces the slow degradation pattern described earlier — gradually rising response times, increasing database query durations, more frequent usage limit warnings — that is easy to rationalize away one data point at a time until the accumulated drift becomes impossible to ignore.
Both types of challenge are addressable, and both are significantly more manageable when recognized early. The monitoring practices covered in app performance monitoring for startups are the mechanism for catching sustained growth degradation before it becomes a crisis, in the same way that understanding your infrastructure’s capacity ceiling is the mechanism for preparing for spikes before they arrive.
How BaaS platforms handle the traffic spike for you
The traditional answer to a scalability problem was to hire a DevOps engineer, provision additional servers, configure load balancers, set up database replicas, and build an auto-scaling policy that could respond to traffic surges in real time. Done well, this infrastructure could handle almost any growth scenario. Done poorly — or not done at all because the team was too small and too busy — it became the single most common reason technically sound products failed at the moment of their first real success.
Backend as a Service platforms exist, in large part, to remove this problem from the founder’s plate entirely. The infrastructure engineering that once required a dedicated specialist and weeks of configuration is absorbed into the platform layer, leaving founders and their development teams to focus on the product decisions that actually require their specific knowledge and judgment.
Understanding what BaaS platforms do automatically — and where the boundaries of that automation sit — is one of the most practically useful things a non-technical founder can know about their infrastructure.
Auto-scaling: the infrastructure that grows with you
The core mechanism that makes BaaS platforms scalable by default is auto-scaling — the ability to automatically provision additional compute resources in response to increased demand, without manual intervention.
In practical terms, this means that when your app experiences a sudden surge in traffic, the platform detects the increased load and spins up additional server capacity to absorb it. When the surge subsides, that additional capacity scales back down. The whole process happens in the background, typically within seconds to minutes of the demand change, without any action required from you or your team.
For a founder, the business implication of auto-scaling is significant. The infrastructure ceiling that would previously have been a fixed constraint — the point at which your provisioned servers simply could not handle more requests — becomes a dynamic boundary that adjusts to your actual usage. Your app does not break when traffic doubles unexpectedly. It flexes to accommodate the demand and then returns to its normal operating footprint.
The analogy that makes this concrete is a taxi company that can instantly clone its entire fleet when demand spikes. Rather than turning customers away because every car is occupied, the fleet expands to meet the demand and contracts again when the rush passes. The customer experience is consistent regardless of whether it is a quiet Tuesday afternoon or the end of a major event. Auto-scaling gives your app the same property.
Managed databases: removing the most fragile link in the chain
As established in section two, the database is typically the first bottleneck to break under unexpected load. Connection limits fill up, query queues grow, and what was a fast, responsive data layer becomes the source of cascading delays across the entire application.
BaaS platforms address this through managed database infrastructure that handles connection pooling, read replicas, and automatic failover without any configuration required from your team. Connection pooling is the mechanism that allows many simultaneous application requests to share a smaller number of actual database connections efficiently — think of it as a shared car service that gets more people to their destination using fewer vehicles than if everyone drove separately. Read replicas are duplicate copies of your database that handle read-heavy queries — fetching data rather than writing it — so that the primary database is not doing all the work alone.
The result is a database layer that handles significantly more concurrent load than a basic single-instance setup, with the platform managing the complexity of keeping replicas synchronized and routing queries appropriately. For a founder who has never managed a database in their life, this means the most technically demanding part of scaling infrastructure is handled before the problem ever arrives.
Global infrastructure: performance at scale without geography becoming a ceiling
A scalability challenge that receives less attention than raw traffic capacity is geographic scale — the problem of maintaining consistent performance for a user base that is spread across multiple regions and time zones. An app that scales its compute capacity to handle more users but still routes all of those users’ requests through a single regional server will still deliver degraded performance to users far from that server, regardless of how much compute has been provisioned.
BaaS platforms address this through globally distributed infrastructure that routes requests to the nearest available server and distributes static content through CDN edge locations around the world. The practical effect, as covered in detail in the context of making your app fast for users everywhere with a CDN, is that geographic distance stops being a hard constraint on your app’s performance. A user in Singapore and a user in São Paulo both get responses from infrastructure close to them rather than from a single origin server that is close to neither.
For founders targeting international markets from early on, or whose products are gaining unexpected traction in regions they did not specifically target, this geographic resilience is one of the most valuable properties a BaaS platform provides — and one that would require significant dedicated infrastructure work to replicate on a self-managed stack.
Where BaaS auto-scaling has limits
Intellectual honesty requires acknowledging that BaaS auto-scaling is not a complete solution to every scalability challenge. There are scenarios where the platform’s automatic behavior is not sufficient and where more deliberate infrastructure decisions are required.
The most common limitation is plan-level resource caps. Most BaaS platforms implement auto-scaling within the boundaries of a given plan tier. A starter plan may auto-scale up to a certain threshold of compute or database connections and then stop, because the plan is not provisioned for demand beyond that ceiling. This is not a flaw in the platform — it is how pricing tiers are structured. The implication for founders is that auto-scaling is a buffer against unexpected spikes, not an unlimited capacity guarantee.
A second limitation involves database write performance under extreme concurrent load. Read operations — fetching data — scale relatively gracefully through read replicas and caching. Write operations — creating and updating records — are more constrained because they must go through the primary database to maintain data consistency. An app with an unusually high ratio of write to read operations, such as a real-time collaborative tool or a high-frequency transaction platform, may encounter database write bottlenecks that require more advanced architectural solutions beyond what standard BaaS auto-scaling provides.
Understanding these boundaries is not a reason to distrust BaaS platforms as a scaling foundation. For the vast majority of SaaS products at early and mid-stage scale, the automatic infrastructure management BaaS provides is more than sufficient. It is simply useful to know where the boundaries are so that the decision to move beyond them — through a plan upgrade, a specialized database configuration, or an architectural change — is made deliberately rather than discovered under pressure.
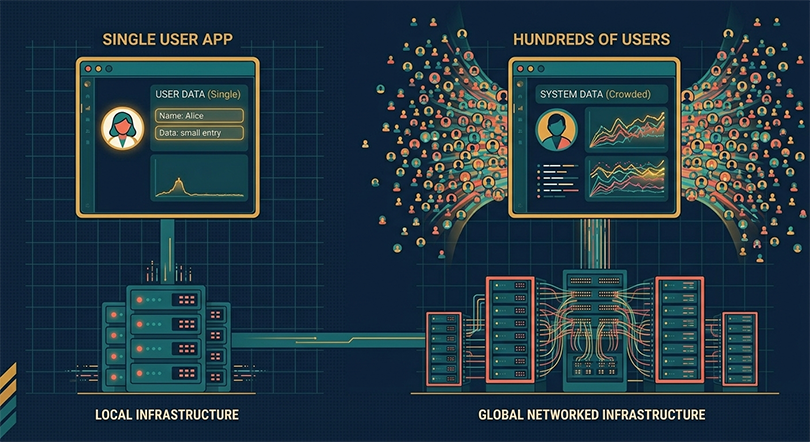
The three layers of scale: users, data, and geography
Scalability conversations tend to default to a single metric: user count. How many users can your app handle? At what number of users do you need to upgrade? When does your current plan run out of headroom? These are reasonable questions, but they frame scalability as a one-dimensional problem when it is actually three-dimensional.
A growing SaaS product scales across three distinct layers simultaneously, and each layer has its own failure modes, its own warning signs, and its own set of solutions. Understanding the difference between them changes how you read your infrastructure metrics, how you prioritize your technical investments, and how you have conversations with your team or your BaaS platform’s support documentation when something starts to feel wrong.
The three layers are users, data, and geography. They interact with each other, but they are not the same problem, and solving one does not automatically solve the others.
Layer one: user scale
User scale is the dimension most founders think about first because it is the most visible. More users mean more concurrent sessions, more simultaneous requests, more strain on compute and memory, and more demand on the database connection pool. The infrastructure challenges described in section two — server bottlenecks, database connection limits, memory saturation — are primarily expressions of user scale pushing against capacity ceilings.
The useful metric for thinking about user scale is not your total registered user count but your peak concurrent active users — the maximum number of people using your app simultaneously at any given moment. A product with fifty thousand registered users but a highly distributed global audience might have a peak concurrency of two hundred users at any given time. A product with five thousand registered users but a concentrated audience in a single time zone might have peak concurrency of eight hundred during the morning rush.
Peak concurrency is what your infrastructure actually needs to be sized for, because that is the load your systems must handle without degrading. A common early-stage mistake is provisioning infrastructure based on total user count rather than realistic peak concurrency estimates, which either leads to over-provisioning that wastes budget or under-provisioning that creates performance problems during predictable high-traffic windows.
BaaS platforms handle user scale primarily through the auto-scaling mechanisms described in section three. The practical founder task at this layer is monitoring peak concurrency trends over time — watching whether your highest-traffic hours are pushing response times upward — and using that data to anticipate when your current plan’s ceiling will become a constraint. The growth audit framework covered in the final section of this article gives you a structured way to make that assessment.
Layer two: data scale
Data scale is the dimension that surprises founders most often because it grows independently of user activity in ways that are not always intuitive. Every user interaction that writes something to your database — a login event, a form submission, a transaction record, a notification — adds to the accumulated data volume your app must search through on every query. Over time, even a product with modest user growth can accumulate a database that is orders of magnitude larger than it was at launch.
The performance impact of data scale is qualitatively different from the impact of user scale. User scale tends to produce acute problems — sudden slowdowns during peak traffic, connection limit errors during spikes — that are relatively easy to diagnose and correlate with traffic events. Data scale tends to produce chronic problems — a gradual drift toward slower query times, increasing database response latency, subtly degraded search and filter performance — that accumulate slowly and are easier to rationalize away one data point at a time.
The three primary mechanisms for managing data scale are indexing, archiving, and query optimization, all of which are covered in depth in the context of database optimization for startups. At the infrastructure level, data scale also has direct implications for your BaaS plan’s storage allocation and database compute provisioning. A database that has grown to tens of millions of rows requires more compute to query efficiently than one with hundreds of thousands, even if the number of users making those queries has not changed.
One of the most underappreciated aspects of data scale for non-technical founders is that it is largely within your control through product and policy decisions. What data does your app actually need to retain, and for how long? Are there categories of historical data — session logs, notification records, ephemeral activity events — that accumulate indefinitely but serve no ongoing purpose after a certain age? Building data retention policies into your product from early on is one of the highest-leverage decisions a founder can make for long-term data scale management, and it costs nothing to implement early compared to the significant effort of retrofitting it onto a database that has already accumulated years of unmanaged growth.
Layer three: geographic scale
Geographic scale is the dimension that becomes relevant the moment your user base extends beyond a single region, and it operates through a fundamentally different mechanism than user or data scale. Adding more compute capacity or optimizing your database does nothing for a user in Sydney whose requests are traveling to a server in Virginia. The problem is not capacity — it is physics.
As covered in the context of CDN infrastructure and global performance, geographic scale is addressed through distribution rather than provisioning. The solution is not a bigger server in one place but the same content available from many places, each closer to a segment of your users. BaaS platforms handle the static content layer of this through their built-in CDN infrastructure. The more nuanced geographic scale challenge is dynamic content — API responses, database queries, real-time features — that cannot be pre-distributed to edge locations because it depends on live data.
For most early and mid-stage SaaS products, the static content CDN coverage provided by BaaS platforms addresses the majority of geographic performance concerns. The remaining gap — dynamic content latency for users far from the origin server — becomes a meaningful product concern when the product is genuinely global and when the dynamic interactions are latency-sensitive enough that the extra round-trip time creates a perceptible degradation in experience.
The geographic scale question worth asking as a founder is where your users actually are versus where you assumed they would be when you selected your BaaS region at setup. Checking your analytics for the geographic distribution of your active users is a five-minute task that occasionally reveals that a significant portion of your user base is sitting in a region you did not specifically provision for — a finding that is much more actionable when discovered through a deliberate audit than when surfaced by a cluster of performance complaints.
How the three layers interact
The reason it is useful to separate these three dimensions is that they require different solutions. But it is equally important to understand that they interact, and that pressure in one layer often amplifies pressure in another.
High user scale combined with high data scale is the most common compounding scenario. When many users are simultaneously querying a large, unoptimized database, the response time impact is multiplicative rather than additive. The concurrency pressure from the user layer and the search inefficiency from the data layer combine to produce slowdowns that are significantly worse than either factor alone would produce. Addressing only one — adding more compute without optimizing the database, or optimizing the database without addressing concurrency — produces only partial improvement.
Geographic scale interacts with both other layers in the sense that users far from the origin server experience the latency of their geographic distance on top of whatever response time the user and data layers are already producing. A two-second response time that is acceptable for a user close to the server might translate to a four-second experience for a user halfway around the world, crossing the threshold from tolerable to frustrating without anything in the infrastructure having technically changed.
Thinking about scalability across all three layers simultaneously — asking not just “how many users can this handle” but also “how will performance hold up as data accumulates” and “how does this perform for users who are not geographically close to my server” — is the shift in perspective that separates founders who scale smoothly from those who are perpetually surprised by infrastructure problems that were, in retrospect, entirely predictable.
Planning for growth before it hits: a founder’s checklist
There is a particular kind of founder confidence that comes from having launched successfully, found early traction, and built a product that real users are paying for. It has earned confidence, and it deserves to exist. What it sometimes obscures is the gap between the infrastructure that got you here and the infrastructure that will carry you through the next stage of growth.
Planning for scale is not about assuming you will go viral tomorrow or provisioning for a user base you have not yet earned. It is about closing the gap between where your infrastructure is today and where your growth trajectory suggests it will need to be in the next three to six months — before the gap becomes a crisis rather than a project.
The checklist that follows is designed to be completed by a non-technical founder in a single sitting. It does not require deep technical knowledge. It requires honest answers to concrete questions about your current setup, your growth trends, and the habits your team has or has not built around infrastructure health.
Establish your current performance baseline
Before you can plan for growth, you need an honest picture of where you are starting from. Pull up your BaaS monitoring dashboard and record three numbers: your average response time over the past thirty days, your average error rate over the same period, and your peak concurrent user count during your highest-traffic window of the week.
These three numbers are your baseline. They tell you what normal looks like for your app right now, which is the only reference point that makes future changes meaningful. A response time increase from 400 milliseconds to 600 milliseconds sounds trivial in isolation. Against a baseline that has been stable at 400 milliseconds for three months, it is a signal worth investigating.
If your platform does not surface these metrics clearly, or if you have not yet set up monitoring, establishing that baseline is the first item on the checklist — not because monitoring is a nice-to-have but because operating infrastructure without visibility into its health is the equivalent of running a business without looking at your bank balance. The practices covered in app performance monitoring for startups give you the specific setup steps to get this in place quickly.
Map your growth trajectory against your plan limits
The second checklist item is a straightforward projection exercise. Look at your user growth rate over the past ninety days and extrapolate it forward six months. Then look at your BaaS plan’s published limits — monthly active users, API requests, database storage, concurrent connections — and identify how close your projected usage will sit to those limits at the six-month mark.
This projection does not need to be precise. Its purpose is not to predict the future accurately but to surface whether you are on a trajectory that will require infrastructure decisions in the near term or the medium term. If your growth rate suggests you will hit eighty percent of a plan limit within three months, that is a near-term decision. If the projection shows comfortable headroom for six months or more, you can deprioritize the upgrade conversation and return to it at your next quarterly review.
The projection also reveals which limit you are likely to hit first, which matters because different limits have different solutions. A storage limit is addressed differently than a compute limit, which is addressed differently than a database connection limit. Knowing which constraint is approaching first focuses your preparation on the relevant fix rather than a general infrastructure upgrade that may not address the actual bottleneck.
Audit your caching and CDN configuration
A significant portion of scalability problems can be prevented or delayed through caching and content delivery optimization that many founders have never explicitly configured — and that BaaS platforms may or may not have enabled by default depending on the specific plan and setup.
The audit here is simple. Confirm that your BaaS platform’s CDN is active for your static assets. Check whether caching is enabled for your most frequently accessed API endpoints. Review whether your app has any data fetching patterns that treat frequently-requested, rarely-changing data as if it were real-time — profile data, plan information, static content — and consider whether those patterns are preventing the platform’s caching layer from doing its job effectively.
The short version for this checklist: caching, CDN coverage, and scalability is that properly configured caching and CDN infrastructure can extend the useful life of your current backend plan significantly, reducing how quickly you approach plan limits and improving performance for geographically distributed users without any infrastructure upgrade required. The full picture of what caching actually does for your app’s speed and cost efficiency is worth understanding before concluding that an upgrade is the only path forward.
Review your database health proactively
The database is the layer most likely to degrade quietly and most likely to produce the gradual, hard-to-diagnose slowdowns that erode user experience before they trigger any obvious alerts. A proactive database health review as part of your growth planning gives you a clear picture of whether your data layer is positioned to handle the next stage of growth or whether it is already showing the early signs of strain.
The review involves four specific checks. First, look at your database size growth rate over the past ninety days and project it forward. Second, check whether indexes exist on the columns your app’s most frequent queries are filtering by — your BaaS platform’s dashboard will typically surface missing index recommendations if they exist. Third, review whether you have any data retention policies in place, and if not, identify the categories of data that are accumulating indefinitely without ongoing utility. Fourth, check your slowest queries in the platform’s performance panel and note whether any have gotten significantly slower over the past month.
None of these checks requires SQL knowledge or database administration experience. They are dashboard-level reviews that surface actionable information about a layer of your infrastructure that is easy to overlook until it becomes a problem. Building this review into a quarterly rhythm keeps your database health visible and prevents the kind of accumulated drift that produces performance crises at the worst possible moments.
Stress test your most critical user flows
A stress test sounds more technical than it needs to be. At its most basic, it means deliberately putting your app under higher-than-normal load and observing how it behaves — specifically on the flows that matter most to your business. Onboarding, the core value-delivery feature, the payment flow, and the dashboard that users see every day are the candidates.
Most BaaS platforms and the broader developer tooling ecosystem include load testing tools that simulate concurrent users without requiring custom code. Running a test that simulates two to three times your current peak concurrent load for fifteen minutes and watching your monitoring dashboard during the test gives you a direct answer to the question “what happens to my app when growth doubles?” before growth actually doubles.
The goal is not to break your app in a controlled environment for its own sake. It is to identify which component reaches its limit first, at what load level, and with what symptoms — so that if a real traffic spike produces similar symptoms, you recognize them immediately rather than spending critical minutes diagnosing from scratch. Founders who have stress tested their critical flows handle traffic spikes with notably more composure than those encountering the failure modes for the first time under real conditions.
Build an incident response habit before you need one
The final checklist item is the one most founders skip because it feels like premature organizational overhead. It is not. An incident response habit — a simple, documented process for what happens when your app degrades or goes down — is one of the highest-return investments a growing SaaS company can make per hour spent.
The habit does not need to be elaborate. It needs three things: a clear first responder (who gets notified first when a monitoring alert fires), a communication template (what you say to affected users and when), and a post-incident review process (a short, blame-free discussion of what happened and what would catch it earlier next time). That is it. Three elements, documented in a shared location, reviewed after every incident.
The value of this habit compounds with team size. At two people, the first responder is obvious and the communication is informal. At ten people, without a documented process, the first fifteen minutes of every incident are consumed by figuring out who owns the response rather than executing it. Building the habit when the process is simple makes it dramatically easier to maintain as the organization grows.
Scalability planning, at its best, is the practice of treating growth as something you are prepared for rather than something that happens to you. The checklist above does not guarantee that your infrastructure will handle every growth scenario without friction. It does guarantee that you will have better visibility, faster response times to problems, and more deliberate decision-making about infrastructure investments than founders who treat these questions as something to figure out later.
When to upgrade, optimize, or rethink your backend plan
Every infrastructure decision a founder makes eventually arrives at a fork in the road with three paths: upgrade the plan, optimize what you have, or rethink the architecture entirely. Choosing the wrong path wastes time and money. Choosing the right one at the right moment is one of the most consequential operational decisions a growing SaaS company makes, and it is one that non-technical founders are often poorly equipped to navigate because the framing they receive is almost always binary — stay or upgrade — when the reality is more nuanced.
Understanding when each path is appropriate, and what signals point toward which choice, gives you a decision-making framework that works across every stage of growth rather than a one-size answer that fits only the current moment.
When optimization is the right first move
Optimization is the right first response when performance problems are concentrated, specific, and traceable to inefficiencies in how your app uses its current infrastructure rather than to the infrastructure being genuinely insufficient for your load.
The clearest signal that optimization is the appropriate path is when performance degradation is isolated to specific features or time windows rather than distributed across the entire app. If your dashboard loads slowly but your onboarding flow is fast, the problem is almost certainly in how the dashboard fetches its data — a query optimization or caching opportunity — rather than in your overall infrastructure capacity. Upgrading your plan in response to a problem that optimization would solve is the infrastructure equivalent of buying a bigger warehouse because the existing one is disorganized. The space is not the problem. The organization is.
The second signal that optimization should come before upgrading is when your BaaS dashboard is surfacing specific, actionable recommendations — missing indexes, slow queries, high cache miss rates — that have not yet been addressed. These recommendations represent known inefficiencies that your platform has already identified. Acting on them before upgrading ensures that you are comparing the performance of an optimized system on the current plan against the cost of the next tier, rather than paying for an upgrade to mask problems that optimization would have solved for free.
Optimization has a ceiling, however. Once the obvious inefficiencies have been addressed — caching is configured, indexes are in place, data retention policies are managing accumulation, queries have been reviewed — and performance problems persist, the infrastructure itself has become the constraint. At that point, optimization returns diminishing results and the conversation shifts to upgrading.
When upgrading is the clear answer
Upgrading is the right move when your infrastructure is well-optimized and the constraint is genuinely capacity rather than efficiency. The distinction matters because upgrading an unoptimized system produces less improvement than the cost suggests — you are paying for more capacity to run an inefficient system, which is a worse outcome than paying the same amount to run an efficient one.
Assuming optimization has been addressed, the signals that point clearly toward upgrading are the ones covered in depth in the [growth audit for founders]: consistent response time increases that track with usage growth rather than specific features, regular approach to plan usage limits, monitoring alerts that have become routine rather than exceptional, and engineering time being spent managing infrastructure rather than building product.
The upgrade decision also has a timing dimension that founders often underweight. Upgrading from a position of comfortable headroom — when you have three to four months before a limit becomes a genuine constraint — is categorically different from upgrading reactively after performance has already degraded. The proactive upgrade happens on your schedule, with time to verify the new configuration, monitor the improvement, and communicate proactively with your team. The reactive upgrade happens under pressure, with users already affected and the urgency of the moment compressing the time available for careful execution.
The growth audit checklist from the previous section gives you the structured process for identifying where you sit on that timing spectrum. Using it quarterly transforms the upgrade decision from a reactive crisis into a planned operational event.
When rethinking the architecture is necessary
Rethinking the architecture is the path that most early-stage founders will not need to take, and it is worth being clear about that upfront so the concept does not create unnecessary anxiety. The vast majority of SaaS products can be carried through their first several years of growth on a well-chosen BaaS platform with periodic plan upgrades and consistent optimization habits. Architectural rethinking is a later-stage concern, relevant when a product has genuinely outgrown what managed platforms can provide.
The signals that point toward architectural reconsideration are qualitatively different from those that point toward optimization or upgrading. They involve fundamental mismatches between the product’s technical requirements and the capabilities of the current platform category — not just the current plan. A real-time collaborative product that requires sub-ten-millisecond latency for its core interactions may eventually need edge computing infrastructure that goes beyond what standard BaaS CDN coverage provides. A platform handling financial transactions at very high frequency may need database architecture specifically optimized for write-heavy workloads rather than the general-purpose databases most BaaS platforms offer.
These are genuine architectural questions, but they arrive after significant scale and with enough time to plan a deliberate migration. They are not the infrastructure emergency that early-stage founders fear when they first encounter the concept of scalability. For the overwhelming majority of founders reading this, the relevant question is not whether to rethink the architecture but whether to optimize, upgrade, or both — and the answer to that question is available in your BaaS dashboard right now.
Making the decision without a technical co-founder
One of the persistent anxieties for non-technical founders is the feeling that infrastructure decisions require technical expertise they do not have. The framework above is designed specifically to address that anxiety by replacing technical judgment with business judgment — which is something every founder already has.
Optimization versus upgrade versus rethink is fundamentally a question about where the constraint lives: in the efficiency of the system, in the capacity of the plan, or in the fundamental architecture. Each of those constraints produces different symptoms, surfaces different signals in your dashboard, and responds to different solutions. Reading those signals does not require knowing how a database engine works. It requires the same diagnostic instinct you would apply to any business operation that is underperforming — identify the bottleneck, apply the targeted fix, verify the result.
The BaaS platform is your infrastructure partner in this process, not just a vendor. The dashboard, the performance recommendations, the usage metrics, and the support documentation are all designed to make these decisions accessible to founders without deep technical backgrounds. Using those tools deliberately and consistently is the non-technical founder’s equivalent of having a strong DevOps engineer on staff — not identical, but far closer than most founders realize.
Sum-up
Scalability is not a problem you solve once and file away. It is a relationship between your product’s growth and your infrastructure’s capacity that requires ongoing attention, periodic reassessment, and the willingness to act on what your data is telling you before circumstances force your hand.
The mental models in this article — scalability as a relationship rather than a fixed property, the three layers of user scale, data scale, and geographic scale, the distinction between optimization and upgrading, the growth audit as a quarterly habit — are not technical concepts dressed up in business language. They are genuinely business concepts that happen to have infrastructure implications. A founder who understands them is not pretending to be a backend engineer. They are doing their job as a product leader who takes operational resilience seriously.
The founders who scale smoothly are not the ones who got lucky. They are the ones who treated their infrastructure with the same deliberate attention they gave their product. That starts with understanding what scalability actually requires — which is exactly what you now have.
About the Author

AISalah
Bridges linguistics and technology at PointOfSaaS, exploring AI applications in business software. English Studies BA with hands-on back-end and ERP development experience.
Did you find this helpful?
Your feedback helps us curate better content for the community.